
Toward Vehicle-Agnostic Driving Signatures for Cognitive Impairment Prediction from Naturalistic Driving Data
Washington University in St. Louis, Spring 2026
Master’s thesis completed in the Department of Computer Science & Engineering at Washington University in St. Louis (McKelvey School of Engineering), advised by Dr. Alvitta Ottley, with committee members Dr. Ganesh Babulal and Dr. Nathan Jacobs. This work is part of the DRIVES Project at WashU.
Overview
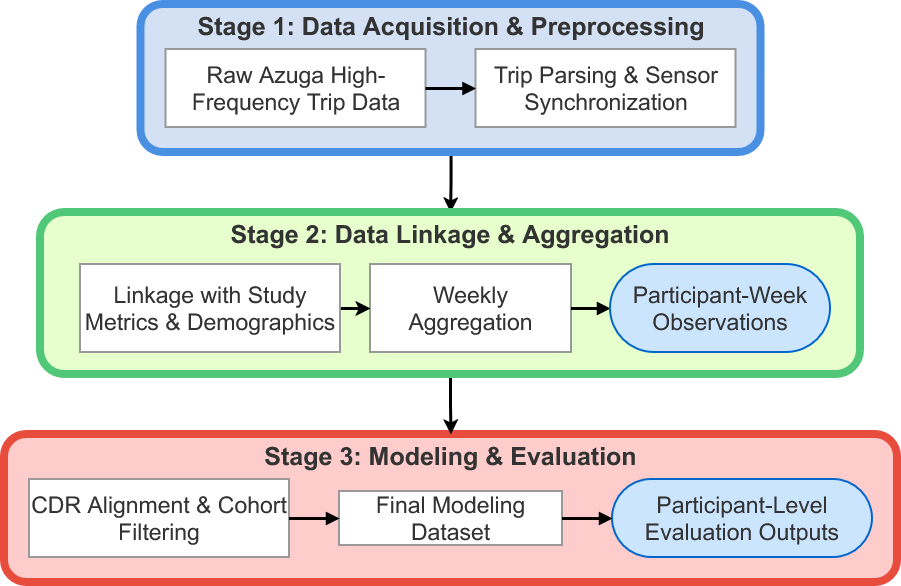
This thesis studies whether naturalistic driving data can help predict binary Clinical Dementia Rating (CDR) status while accounting for differences across vehicles. The final analytic dataset comprised 26,968 participant-weeks from 304 participants (218 healthy, 86 impaired). Weekly driving features were derived from real-world telematics data collected via Azuga dataloggers installed in participants’ personal vehicles, combined with demographic covariates.
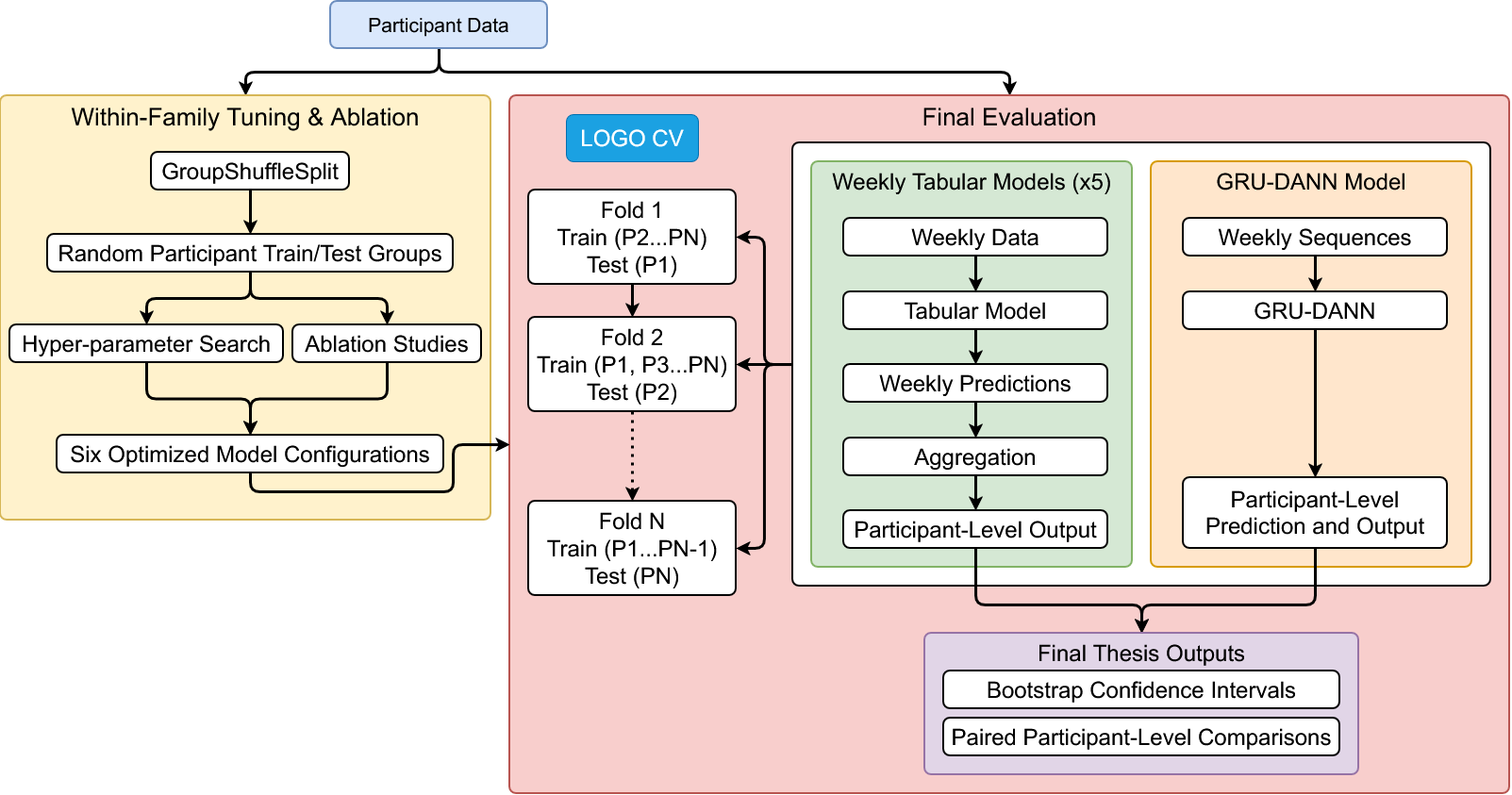
The main comparison includes six model families evaluated under leave-one-participant-out (LOGO) cross-validation: Logistic Regression, XGBoost, Random Forest, MLP, DANN (Domain-Adversarial Neural Network), and GRU-DANN (sequence-aware variant). Performance remained modest overall, with all models falling in a narrow ROC AUC range of 0.50–0.60.
Key Contributions
- Technical: Formulates vehicle heterogeneity as a domain shift problem; implements and compares baseline, domain-adversarial, and sequence-based modeling approaches under a rigorous LOGO evaluation framework; develops a reusable feature-engineering pipeline from raw telematics data.
- Clinical: Sharpens the question of whether driving-based biomarkers remain credible when vehicle-linked variation is taken seriously, finding that naturalistic driving data may carry limited information about cognitive status under the current pipeline.
- Data: Procedures for aligning longitudinal driving data with intermittent clinical assessments and incorporating vehicle-level characteristics (make, model, ADAS features) into analytic datasets.
Modeling Approach
The pipeline processes raw Azuga telemetry through three stages: trip segmentation and cleaning, linkage to participant clinical records, and weekly aggregation into 84 behavioral features spanning speed, acceleration, jerk, route complexity, turning patterns, and time-of-day driving behavior. Vehicle identity is incorporated as a domain label, with 428 unique vehicles clustered into four domain groups based on shared characteristics.
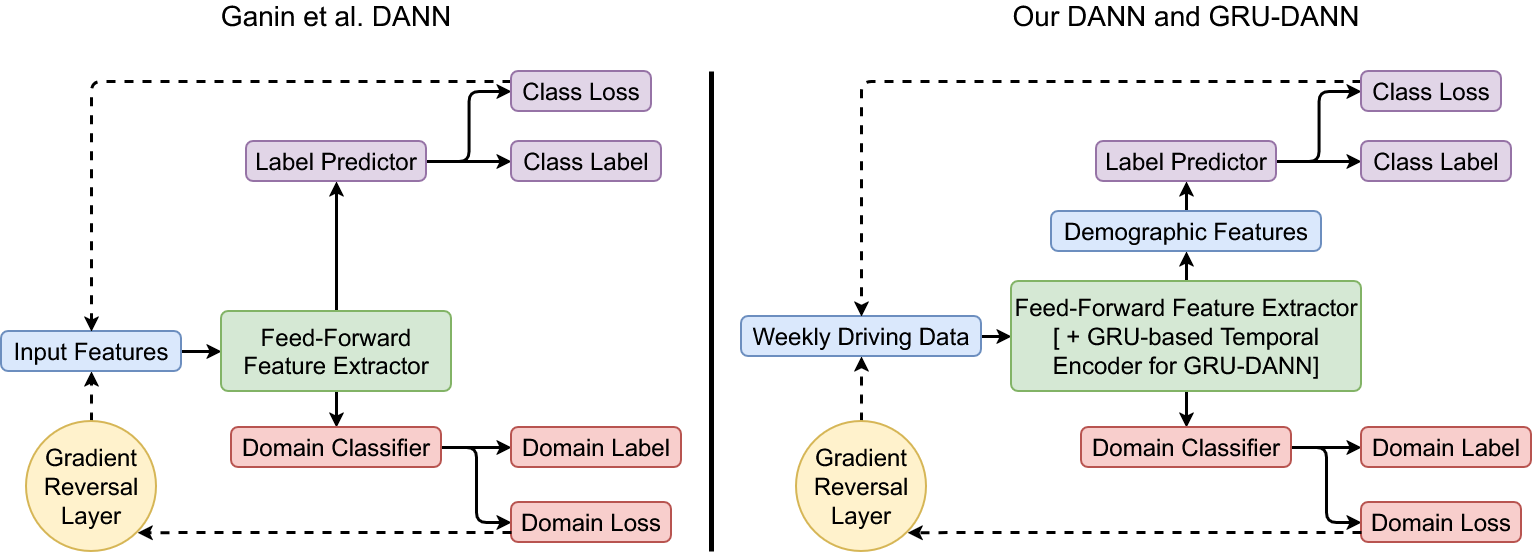
Six model families were compared: three classical baselines (Logistic Regression, XGBoost, Random Forest), a multilayer perceptron (MLP), a domain-adversarial neural network (DANN), and a sequence-aware GRU-DANN that processes driving data as weekly sequences while simultaneously learning vehicle-invariant representations.
Results
Evaluation used leave-one-participant-out (LOGO) cross-validation, with one individual held out at a time and participant-level metrics pooled as the primary reporting surface. Bootstrap confidence intervals and paired DeLong tests were used for statistical comparison.
| Model | ROC AUC | PR AUC | Balanced Accuracy | Sensitivity | Specificity |
|---|---|---|---|---|---|
| Logistic Regression | 0.586 | 0.345 | 0.576 | 0.523 | 0.628 |
| XGBoost | 0.502 | 0.292 | 0.506 | 0.209 | 0.803 |
| Random Forest | 0.595 | 0.355 | 0.535 | 0.198 | 0.872 |
| MLP | 0.573 | 0.337 | 0.527 | 0.186 | 0.867 |
| DANN | 0.554 | 0.327 | 0.522 | 0.209 | 0.835 |
| GRU-DANN | 0.599 | 0.346 | 0.584 | 0.512 | 0.656 |
Bold indicates best in column. GRU-DANN achieved the highest ROC AUC (0.599) and balanced accuracy (0.584), while Logistic Regression led on sensitivity (0.523) and Random Forest on specificity (0.872). All 95% confidence intervals overlap substantially; overall discriminative performance is modest.
Committee
- Chair: Dr. Alvitta Ottley, Department of Computer Science & Engineering
- Member: Dr. Ganesh Babulal, Department of Neurology
- Member: Dr. Nathan Jacobs, Department of Computer Science & Engineering